

Job Readers & Writers
Job Readers and Job Writers are designed to communicate to source and target systems supported by
DataZen. A Job Reader Job fetches data from the source system at the specified interval, when started
manually, or automatically for messaging consumers. Job Readers then forward data extracted from the
source system as-is, or forwards the data to the DataZen Change Data Capture (CDC) Engine to extract
changes automatically (a.k.a. Synthetic CDC). If a change is detected in the source data, a Sync File is
produced in the specified output directory.
Change Logs and Sync Files are used interchangeably throughout the documentation.
Change Logs hold the changes that were detected from the source system and stored in a universal
format so that the changes can be played back on any target system. When first created, the Change Log may
contain all the records from the source system. To learn more about Sync Files, see the Data Sync Files
section.
Job Writers start on a schedule and inspect a shared folder for new Sync Files; they can also be started
upon completion of a Job Reader using a Job Trigger. When a new Change Log has been detected, the
Job Writer extracts the data found in the log, converts each record in the format expected by the target
system, and executes the necessary command(s) against the target system.
When the target system is a relational database, an Upsert operation is either an Insert or an Update operation depending on whether the record is found in the target system or not based on the Key Columns specified.
This architecture allows Job Readers and Job Writers to reside on entirely different networks, with only a network share or cloud folder (or an FTP site) in common. Because the Change Log can also be encrypted using PGP, the Change Log can also be stored on any public cloud platform.
Job Types
Once a Data Sync agent has been configured and registered in DataZen Manager, you can start managing Job Readers and Job Writers. The following types of jobs can be created:
-
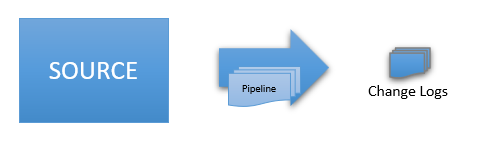
Job Reader – reads data from a source system, performs Synthetic CDC if needed,
runs the Data Pipeline if any, and stores data in a Sync File (the Change Log).
Once created, the Sync File can be used by Job Writers.
-
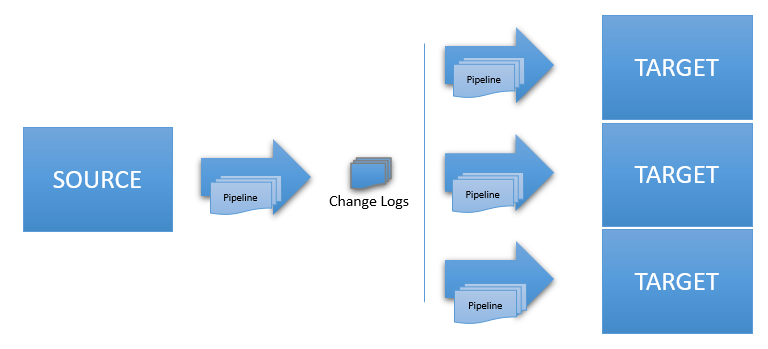
Job Writer - a job that reads data stored in a Sync File (the Change Log), applies an
optional secondary Data Pipeline (if defined) and sends the data to a target system;
multiple writers can reade from the same file.
-
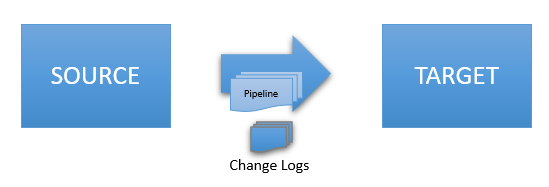
Direct Job - a job that defines both a job reader and a job writer
(creates a Sync File that can optionally be deleted upon completion); a single Data Pipeline is executed
(if any)
-
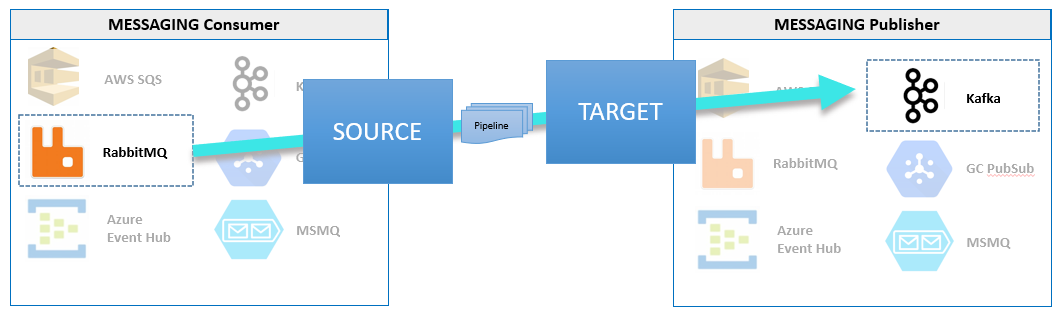
Passthrough Consumer - a simpler Job Reader that forwards messages from
one messaging platform to another, with an optional Data Pipeline, (does not create a Sync File)
When creating a job (reader and/or writer) DataZen will provide different options
depending on the system it is connecting to. DataZen can communicate with the following
systems:
- Relational Database / ODBC / Enzo Server
- HTTP/S REST API
- File (CSV, Parquet, XML, JSON)
- Big Data / NO-SQL Databases
- Messaging Platforms